

RAID Information - Basic RAID Levels
- Index
- Definitions
- Basic RAID Levels
- Compound RAID Levels
![]()
| |
|
| |
|
RAID Information - Basic RAID Levels
|
|
Some disk controller manufacturers incorrectly use the term JBOD to refer to a Concatenated array.
The good point of a Concatenated array is that different sized disks can be used in their entirety. The RAID arrays below require that the disks that make up the RAID array be the same size, or that the size of the smallest disk be used for all the disks.
The individual disks in a Concatenated array are organized as follows:

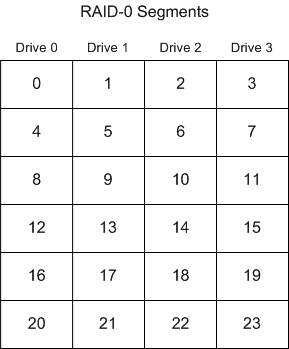
The I/O performance of a RAID-0 array is significantly better than a single disk. This is true on small I/O requests, as several can be processed simultaneously, and for large requests, as multiple disk drives can become involved in the operation. Spindle-sync will improve the performance for large I/O requests.
This level of RAID is the only one with no redundancy. If one disk in the array fails, data is lost.
The individual segments in a 4-wide RAID-0 array are organized as follows:
A RAID-1 array normally contains two disk drives. This will give adequate protection against drive failure. It is possible to use more drives in a RAID-1 array, but the overall reliability will not be significantly effected.
RAID-1 arrays with multiple mirrors are often used to improve performance in situations where the data on the disks is being read from multiple programs or threads at the same time. By being able to read from the multiple mirrors at the same time, the data throughput is increased, thus improving performance. The most common use of RAID-1 with multiple mirrors is to improve performance of databases.
Spindle-sync will improve the performance of writes. but have virtually no effect on reads. The read performance for RAID-1 will be no worse than the read performance for a single drive. If the RAID controller is intelligent enough to send read requests to alternate disk drives, RAID-1 can significantly improve read performance.
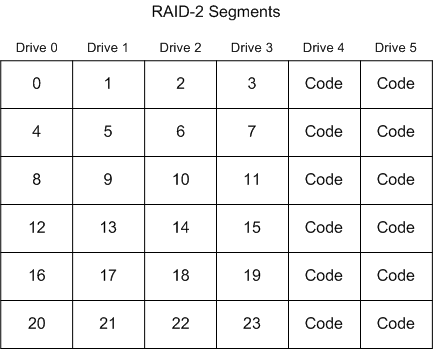
Instead of using a simple parity to validate the data (as in RAID-3, RAID-4 and RAID-5), it uses a much more complex algorithm, called a Hamming Code. A Hamming code is larger than a parity, so it takes up more disk space, but, with proper code design, is capable of recovering from multiple drives being lost. RAID-2 is the only simple RAID level that can retain data when multiple drives fail.
The primary problem with this RAID level is that the amount of CPU power required to generate the Hamming Code is much higher then is required to generate parity.
A RAID-2 array has all the penalties of a RAID-4 array, with an even larger write performance penalty. The reason for the larger write performance penalty is that it is not usually possible to update the Hamming Code. In general, all data blocks in the stripe modified by the write, must be read in, and used to generate new Hamming Code data. Also, on large writes, the CPU time to generate the Hamming Code is much higher that to generate Parity, thus possibly slowing down even large writes.
The individual segments in a 4+2 RAID-2 array are organized as follows:
During a write, RAID-3 stores a portion of each block on each data disk. It also computes the parity for the data, and writes it to the parity drive.
In some implementations, when the data is read back in, the parity is also read, and compared to a newly computed parity, to ensure that there were no errors.
RAID-3 provides a similar level of reliability to RAID-4 and RAID-5, but offers much greater I/O bandwidth on small requests. In addition, there is no performance impact when writing. Unfortunately, it is not possible to have multiple operations being performed on the array at the same time, due to the fact that all drives are involved in every operation.
As all drives are involved in every operation, the use of spindle-sync will significantly improve the performance of the array.
Because a logical block is broken up into several physical blocks, the block size on the disk drive would have to be smaller than the block size of the array. Usually, this causes the disk drive to need to be formatted with a block size smaller than 512 bytes, which decreases the storage capacity of the disk drive slightly, due to the larger number of block headers on the drive.
RAID-3 also has configuration limitations. The number of data drives in a RAID-3 configuration must be a power of two. The most common configurations have four or eight data drives.
Some disk controllers claim to implement RAID-3, but have a segment size. The concept of segment size is not compatible with RAID-3. If an implementation claims to be RAID-3, and has a segment size, then it is probably RAID-4.
For reads, and large writes, RAID-4 performance will be similar to a RAID-0 array containing an equal number of data disks.
For small writes, the performance will decrease considerably. To understand the cause for this, a one-block write will be used as an example.
It can be seen from the above example that a one block write will result in two blocks being read from disk and two blocks being written to disk. If the data blocks to be read happen to be in a buffer in the RAID controller, the amount of data read from disk could drop to one, or even zero blocks, thus improving the write performance.
The individual segments in a 4+1 RAID-4 array are organized as follows:

RAID-5 has all the performance issues and benefits that RAID-4 has, except as follows:
The individual segments in a 4+1 RAID-5 array are organized as follows:

The above block layout is an example of Linux RAID-5 in left-asymetric mode. For additional information on Linux RAID-5 algorithms, please look here.
For information on data recovery for errors and failed disks, please look here.
| Prev | Index | Next |
If you have any comments or suggestions, please E-mail webmaster@accs.com